Time Series Conventions
This section covers the conventions for both regular- and irregular-interval time series data. There are four data types that are recognized by DSS, and are listed in the table:
Data Type | Description | Example |
PER-AVER | Period average | Monthly Flow |
PER-CUM | Period cumulative | Incremental Precipitation |
INST-VAL | Instantaneous value | Stages |
INST-CUM | Instantaneous cumulative | Precipitation Mass Curve |
In the image below the upper graph shows INST-CUM data that increases as the values increase over time. This could be a rain gage filling up over time.
The bottom graph shows the PER-CUM (incremental 1 hour Precipitation over time).
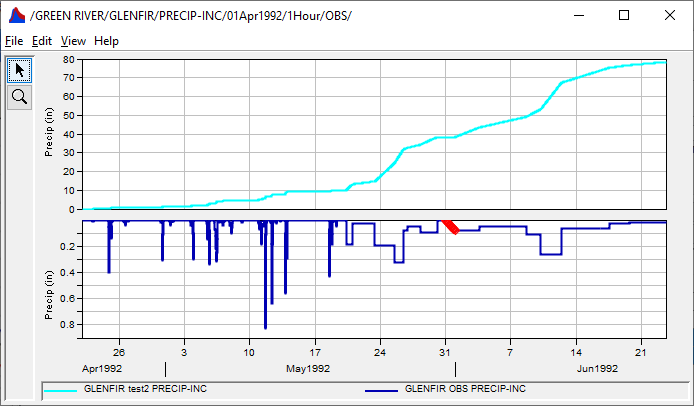
For more examples the the HMS user manual Time-Series section: Time-Series Data v4.4
Default Pathname Parts
Both regular- and irregular-interval time series record pathnames have the same A, B, C, and F parts. Data blocks are labeled with a six part pathname. The parts are referenced by the characters A, B, C, D, E, and F, and are separated by a slash "/", so that a pathname would look as follows:
/A/B/C/D/E/F/
The default conventions for the pathname parts are outlined in the following sections:
Part A – Group
Part A is required for regular- and irregular-interval time series data and is used as a way to group records. Usually this information is a watershed name, study name, project, river, or basin name; a name that allows the user to group associated records.
Part B - Location
Part B is required for regular- and irregular-interval time series data and is the basic location identifier, which is generally the site name. A similar identifier, such as a project ID, USGS gage ID, or NWS station ID may be used. Part B is required.
When a hydrograph is routed from one location to another, the recommended Part B is LOC1.LOC2, where LOC1 is the identifier to which the flows are routed, and LOC2 is an identifier for the location from which flows are routed. The second location (.LOC2) is optional. For example, Part B may be left out in situations where there is only one routed hydrograph for a location.
Part C – Parameter
Part C identifies the basic data parameter for regular- and irregular-interval time series data. A dash is used as a sub-separator if further identification is needed. Additional information about the parameter, such
as how it was obtained (e.g., OBSERVED), should be given in Part F. Examples of valid parameters are:
FLOW
ELEV
PH
PRECIP-INC
STAGE
TEMP-AIR
TEMP-WATER
Recommended C-parts for flows associated with stream locations are as follows:
Part C | Description |
FLOW | Total flow |
FLOW-LOC | Local flow; that is, flow generated only from the subbasin that has an outlet at the specified location. |
FLOW-CUM LOC | Cumulative local flow. This is the flow from all subbasins downstream from the nearest upstream reservoirs. |
FLOW-COMB | Combined flow. This is the total flow minus the local flow. |
FLOW-DIVERT | Flow diverted out of the river at this location. |
FLOW-mod | mod is a user-specified modifier for the flow. For example, FLOW-POWER would designate a hydrograph from a power plant, and, FLOW-IN would be for a component of reservoir inflow. |
FLOW-IN | Reservoir inflow. |
FLOW-OUT | Reservoir outflow. |
ELEV-RES | Reservoir elevation. |
STORAGE | Reservoir storage. |
Part D - Block Start Date
Part D identifies the starting date of the data block. For Part D the conventions are different for regular-interval, and irregular-interval time series data.
Part E - Time Interval or Block Length
Part E defines the time interval for regular-interval data or the block length for irregular-interval data.
Part F – Descriptor
Part F is used to provide any additional information about the regular- and irregular-interval time series data. The use of Part F may vary from application to application as appropriate, and may contain several additional qualifying pieces of information separated by a dash "-". If several forms of data exist, such as OBSERVED or FORECAST, PLAN A or TEST 2, they may be reflected in Part F. Generally, the order of multi-descriptors of Part F should be from most to least significant.
Some applications use Part F to store time series ensembles through the use of "collections", a group of similar datasets for the same time window. Typically, ensembles are historical or statistical conditions applied to current conditions for (short term) future conditions. For example, all historical precipitation for current month can be used a future precipitation for a hydrology model to obtain a potential flow dataset for each year.
A collection is implemented by using an F Part naming convention which starts with "C:" followed by the collection sequence, the pipe symbol "|" and then the regular F part. The sequence character string must be 6 characters long and may be simple integers or alpha-numeric strings, but must be unique within the collection and sortable. Characters following the separator will be the same for all members in the collection. DSS is able to identify a member of a collection by its F Part string.
An example collection pathname is:
/YUBA/SMARTSVILLE/FLOW/01JAN1997/1HOUR/C:000042|OPERATION A/
Regular-Interval Time Series Conventions
Regular-interval time series data is stored in "standard size" blocks whose length depends upon the time interval of the data. For example, daily time interval data are stored in blocks of one year (365 or 366 values) while monthly values are stored in blocks of ten years (120 values). If data does not exist for a portion of the full block, the missing values are set to the missing data flag "-901.0".
The starting and ending times of a block correspond to standard calendar conventions. For example, for period average monthly data in the 1950's, Part D (date part) of the pathname would be 01JAN1950, regardless of when the first valid data occurred (e.g., it could start in 1958). The 1960's block starts on 01JAN1960.
Average period data values are stored at the end of the period over which the data is averaged. For example, daily average values are given a time label of 2400 hours for the appropriate day and average monthly values are labeled at 2400 hours on the last day of the month. If values occur for times other than the end-of-period time, that time offset is stored in the header array. For example, if daily average flow reading's are recorded at 6:00 a.m. (i.e., the average flow from 6:01 a.m. of the previous day to 6:00 a.m. of the current day), then an offset of 360 (minutes) will be stored in the header array.
Part D - Block Start Date
Part D should be a nine-character military style date for the start of the standard data block (not necessarily the start of the first piece of data). Valid dates include 01JAN1982, 01MAR1982, and 01JAN1900 for daily data, hourly data, and yearly data. Invalid dates include 01JAN82 (seven characters) and 14APR1982 for daily data (14APR1982 is not the start of a standard daily block).
Part E - Time Interval
Part E consists of an integer number and an alphanumeric time interval specifying the regular data interval. The valid intervals and block lengths are:
| Valid Data Intervals | Seconds In interval | Block Length | Approximate Values Per Block |
| 1Year | 31536000 (365 days) | One Century | 100 |
| 1Month | 2592000 (30 days) | One Decade | 120 |
| Semi-Month | 1296000 (15 days) | 240 | |
| Tri-Month | 864000 (10 days) | 3600 | |
| 1Week | 604800 (7 days) | 520 | |
| 1Day | 86400 | One Month | 30 |
| 12Hour | 43200 | 60 | |
| 8Hour | 28800 | 90 | |
| 6Hour | 21600 | 120 | |
| 4Hour | 14400 | 180 | |
| 3Hour | 10800 | 240 | |
| 2Hour | 7200 | 360 | |
| 1Hour | 3600 | 720 | |
| 30Minute | 1800 | 1440 | |
| 20Minute | 1200 | 2160 | |
| 15Minute | 900 | 2880 | |
| 12Minute | 720 | One Day | 120 |
| 10Minute | 600 | 144 | |
| 6Minute | 360 | 240 | |
| 5Minute | 300 | 288 | |
| 4Minute | 240 | 360 | |
| 3Minute | 180 | 480 | |
| 2Minute | 120 | 720 | |
| 1Minute | 60 | 1440 | |
| 30Second | 30 | 2880 | |
| 20Second | 20 | 4320 | |
| 15Second | 15 | 5760 | |
| 10Second | 10 | 8640 | |
| 6Second | 6 | 14400 | |
| 5Second | 5 | 17280 | |
| 4Second | 4 | 21600 | |
| 3Second | 3 | 28800 | |
| 2Second | 2 | 43200 | |
| 1Second | 1 | 86400 |
DSS Version 6 Valid Data Intervals (Regular-Interval Part E ) | Block Length |
1MIN, 2MIN, 3MIN, 4MIN, 5MIN, 6 MIN, 10MIN, 12MIN | One Day |
15MIN, 20MIN, 30MIN, 1HOUR, 2HOUR, 3HOUR, 4HOUR, 6HOUR, 8HOUR, 12HOUR | One Month |
1DAY | One Year |
1WEEK, 1MON, SEMI-MONTH, TRI-MONTH | One Decade |
1YEAR | One Century |
Examples of regular-interval pathnames are:
a. Daily USGS observed flow for station 0323150 for calendar year 1954 might be named:
/USGS/0323150/FLOW/01JAN1954/1DAY/OBS/
b. Six-hourly forecasted flow may have a pathname of:
/RED RIVER/DENISION/FLOW/01JUN2010/6HOUR/FORECAST/
Irregular-Interval Time Series Conventions
The irregular-interval time series conventions are similar to the regular-interval conventions except that an explicit date and time is stored with each piece of data whereas in regular-interval time series the date and time are implied by the location of the data within the block. Irregular-interval data is stored in variable length blocks while regular-interval data is stored in fixed length blocks. The block lengths are days, months, years, decades, and centuries.
An example of a pathname for irregular-interval data is: /SANTA ANA/PRADO/FLOW/01JAN2008/IR-MONTH/OBS/
The number of values that may be stored in one record is indefinite although it is prudent to choose a size that matches typical data queries. Usually this is less than 5000 data points. The user selects the appropriate block length. For example, if the data to be stored occurred once every 1-2 hours, a monthly block would be appropriate. If data were recorded once or twice a day, use a yearly block.
One would not want to store data that occurred 10-12 or more times a day in a yearly block (about 5000 values) because that may exceed dimension limits in some programs.
All data are stored in variable length blocks that are incremented a set amount when necessary. Initial space for 100 data values is allocated and additional increments are for 50 data values unless otherwise set. (When the 101st data value is added to the record, a new record with a length of 150 values is written.)
Part D - Block Start Date
Part D should be a nine-character military style date for the first day of the standard data block (not necessarily the start of the first piece of data). For example, data stored in a daily block beginning on March 23, 1952 at 3:10 p.m. would have a Part D of 23MAR1952. If the same data were stored in a monthly block, Part D would be 01MAR1952. The same data in a yearly block would have a Part D of 01JAN1952, and as a decade block, 01JAN1950.
Part E - Block Length
Part E indicates the length of the time block for irregular-interval data, whether it is a day, a month, a year, decade, or a century. For irregular-interval data, Part E consists of IR- concatenated with the block length:
| Block Name | Example Frequency |
|---|---|
| Ir-Day | 10 minutes, 15 seconds |
| Ir-Month | hourly |
| Ir-Year | daily, semi-daily |
| Ir-Decade | monthly |
| Ir-Century | annual |
Example: If you were to store 200 data points, that occur every hour starting in 20Jan2010 the following table shows how 'IR-Day' would result in 9 blocks, while 'IR-Month' would allow storing all the data in a single block.
| IR-Day (9 blocks, 24 points per block) | IR-Month (1 block , all 200 points in a single block) |
|---|---|
| /Basin/Location/Flow/20Jan2010/IR-Day/hourly test/ | /Basin/Location/Flow/01Jan2010/IR-Month/hourly test/ |
| /Basin/Location/Flow/21Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/22Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/23Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/24Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/25Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/26Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/27Jan2010/IR-Day/hourly test/ | |
| /Basin/Location/Flow/28Jan2010/IR-Day/hourly test/ |
The same data may be stored in blocks of different lengths. DSS stores these as different records and treats them as a completely different dataset.