GPU Solver
Performance Update
The GPU solver results listed here are from the February 21st build (0.1.0.1506). There were significant speedups in the March 17th build (0.1.0.1576), which have not been reflected in this document yet.
HEC-RAS 2025 now has a GPU solver!
Explainer
A Graphics Processing Unit (GPU) is a specialized processor that can do trillions of simple math calculations per second. GPUs were originally designed to support video games, because developers needed the brute-force math to move hundreds of thousands (now, millions) of pixels on screen many times per second. In more recent years, specialized libraries have been developed to utilize this compute power for scientific and engineering applications.
While programming for the CPU is largely a solved problem (write once - run anywhere), programming for the GPU is still a bit of wild west. Different hardware manufacturers have different software stacks they support, and targeting a GPU is not as simple as selecting it from a drop-down menu. This makes the development process much slower; we had to write an entirely new set of libraries to take advantage of the unique hardware in GPUs.
Our solver utilizes the industry standard NVIDIA CUDA toolkits and libraries, and thus requires a somewhat modern NVIDIA GPU to run. We're targeting CUDA 12.4, which requires a device from (approximately) 2014+ and drivers from 2024+. For more information, see here and here and here. To find out what device and drivers you have, scroll down to the bottom of this document.
Solver
The GPU solver is an explicit solver that is very similar to our CPU explicit solver, shipped with RAS 2025. Our intent is to keep these solvers as similar as possible, because the CPU solver serves as an excellent testing environment and reference implementation for our GPU solver. However, there may be some divergence for performance considerations. There are many hardware differences between a CPU and a GPU, and certain performance-impacting decisions may lead to different implementations on the CPU vs GPU solver. For example, the LTS (local time stepping) performance optimization is default enabled on the CPU, but is practically infeasible on the GPU, and has not been implemented there. This may lead to very minor differences in output.
Even if the reference implementation is identical, results may not be identical to the last digit. Compounding floating point math differences can make solutions diverge in the least significant digits, which may wind up with minuscule stage/velocity differences. If you see large differences in your results, please report them as a bug so we can investigate!
Theory
Explicit solvers compute water transfer across faces each timestep, taking exactly X water out of one cell and giving it to the neighbor. This means the solver must strictly honor the Courant condition, because we can't take more water out of a cell than exists in the cell in the first place (this would make the solution unstable).
Question: As a thought experiment, what would happen to overall runtime if we take a simple model with 100ft cartesian cells and halved the size to 50ft cells?
- Cell count will go up 4x, since four 50ft cells fit in one 100ft cell.
- Timestep has to shrink to honor the new Courant condition. With constant velocities, halving the cell-size will halve your Courant condition. (1/2x)
Multiplying these together, we would expect that halving the linear cell-size (e.g. from 100ft to 50ft) would increase runtime by 8x.
Reality is much more complicated than theory of course, because dry cells, LTS optimizations, and other terms in the equation also contribute to the overall runtime. The important point is that shrinking cell-size rapidly (and non-linearly) increases the amount of computation power we need.
Benchmarks
For this series of benchmarks we built a model in RAS 2025, then ran the CPU and GPU computes headless (without the user interface) to make sure the comparison was as fair as possible. Because both solvers are explicit (and therefore Courant limited), timestep selection should not affect the overall runtime.
Hardware
The test computer is a few years old now, but it's a fairly standard high-end engineering desktop. Hardware differences can dramatically affect results. We're still in the process of gathering data on a wider range of GPUs, and we'll update this document as we learn more.
- CPU: Intel Xeon W-2265 (12c/24t with 3.5Ghz base clock)
- GPU: NVIDIA Quadro RTX 5000 (3072 CUDA cores, 16GB VRAM)
- RAM: 64GB at 2666MT/s
- Storage: 2TB NVME SSD
Model
We started with the Tuolumne River example dataset, and used the mesh generation tools to increase the number of cells. If you haven't tried them out, the Layer tab has a global cell-size modification that's very helpful for these kinds of coarse modifications. Because of limitations on cell stretch/shrink rates for them to match up with Arc constraints, halving the desired cell-size doesn't result in a perfect 4x count (it's closer to 3x in most tests).
Tuolumne
Headless Tuolumne River compute, 24hrs simulation. Ignores property table pre-processor time. CPU solver used 8 cores.
| Cell Count | CPU (2025) | CPU (6.6) | Q. RTX 5000 | Speedup |
|---|---|---|---|---|
| 25k | 14m 13s | 1m 7s | 12.7 | |
| 77k | 1h 39m 2s | 4m 58s | 19.9 | |
| 245k | ~9h * | 22m 51s | 23.6 * |
* Projected duration. CPU solver crashed or went unstable about 25% of the way through the simulation.
These results are extremely encouraging! It wasn't 100% guaranteed that a GPU solver would be appropriate for RAS 2D calculations, since we use an unstructured mesh with large property tables. We designed our meshing and equation sets to allow for large, complicated cells with variable terrain underneath. Any time we hit a decision point for the RAS solver, we favor doing more math to allow for fewer cells. While this is an excellent tradeoff for a CPU, this approach is (somewhat) antithetical to the GPU hardware. GPUs are optimized for incredible amounts of simple math in parallel, but our approach needs more memory bandwidth, branching logic, iterative solutions, and other non-GPU-centric features.
For frame of reference, the largest geometry in this test (245k cells) spent approximately 3 seconds of that 23 minutes pulling data and writing output to HDF5 - a relatively inconsequential amount. Most of the time taken was spent in the solver itself.
This Tuolumne event is mostly in-bank, so many of the cells are dry for most or all of the simulation. The mesh wasn't designed to be a realistic model, but to get a small sense of scaling and relative performance. For the next example, we'll look at an overland flow scenario where more of the system gets wet.
Berryessa
The Berryessa example dataset uses a simple flow hydrograph to represent a dam breach. The water spreads out over most of the domain, giving us a better idea of solver performance when fully wet. We tested this model on a few different GPUs. For a description of the various GPUs, please see the table below.
Headless Berryessa example project compute, 24hrs simulation. Ignores property table pre-processor time. CPU solver used 8 cores.
| Cell Count | CPU (2025) | RTX 3080 | RTX 4080 | RTX 4090 | Q. RTX 5000 | RTX A5500 | RTX 4000 Ada | RTX 6000 Ada | RTX 3500 Ada (M) | RTX 2000 Ada | Tesla V100 | A100 | H100 (PCIe) | H100 (NVL) | H200 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45k | 16m 50s | 58s | 36s | 26s | 1m 10s (14.4x) | 58s | 47s | 49s | 58s | 1m 14s | 29s (34.8x) | 26s | 21s | 19.5s | 19.8s |
| 167k | 7m 54s | 4m 51s | 3m 28s | 12m 50s | 7m 46s | 8m 12s | 7m 56s | 9m 32s | 13m 45s | 4m 45s | 3m 1s | 2m 31s | 2m | 1m 53s | |
| 637k | 1h 8m 47s | 36m 27s | 23m 52s | 1h 11m | 1h 14m 11s | 2h 15m 49s | 57m 15s | 19m | 15m 40s | 12m 15s | 10m 17s |
Some details to note:
- RTX 4000 Ada and 3500 Ada Mobile, despite being a smaller number than the Quadro RTX 5000, are both faster than it. Newer generations of GPUs come with much improved architectures, so don't just expect "bigger number means better". Of course, within generations, typically bigger numbers are better, and desktop GPUs perform better than laptop GPUs because of higher power budgets and more thermal headroom.
- RTX 6000 Ada is a much more powerful (and expensive) GPU than the RTX 4000 Ada, but isn't any faster for this model, no matter which cell size. (The results we're getting are considered within the noise.) This implies that the runtime is fundamentally limited by something else - memory bandwidth, latency, register pressure, etc. One might reasonably expect that the better GPU goes faster for a sufficiently large problem size (that was certainly our hypothesis!), but that data didn't support that theory for this model. It's entirely possible that 650k cells just isn't large enough to stretch the RTX 6000's legs. We need to study this discrepancy further.
- The relatively ancient Tesla V100 is still wildly fast in this test, over performing workstation cards at smaller model sizes. It has extremely high memory bandwidth but fewer compute units, indicating (as we expected) that our model is mostly memory bandwidth constrained.
- The H100 is an ML / "AI" GPU. It's extremely expensive, highly sought-after, and absolutely overkill for the purpose. But wow, is it fast.
- Extra VRAM doesn't help in the slightest (at these test sizes).
Your selection of GPU should consider the types and sizes of models you expect to use. You can rent them from a variety of cloud services to benchmark your uses, typically for $.20 to $2.00 per hour.
GPU Comparison
This is the set of GPUs we've been testing with so far (sorted by release date).
| Model | Class | Year | CUDA Cores | VRAM | Memory Bandwidth | Bandwidth/Core | Compute (FP32) | Compute (FP64) | Details |
|---|---|---|---|---|---|---|---|---|---|
| Tesla V100 | Datacenter | 2017 | 5120 | 16GB | 900 GB/s | .176 GB/s | 14 TFLOPS | 7 TFLOPS (1/2) | Link, Details |
| Quadro RTX 5000 | Workstation | 2018 | 3072 | 16GB | 448 GB/s | .146 GB/s | 11.2 TFLOPS | 175 GFLOPS (1/64) | Link |
| RTX 3080 | Consumer/Gaming | 2020 | 8960 | 12GB | 760 GB/s | .085 GB/s | 29.8 TFLOPS | 465 GFLOPS (1/64) | Link |
| RTX A6000 | Workstation | 2020 | 10752 | 48GB | 768 GB/s | 38.7 TFLOPS | 605 GFLOPS (1/64) | Link, Link | |
| A100 | Datacenter | 2021 | 6912 | 40-80GB | 1.5-2.0 TB/s | 19.5 TFLOPS | 9.7 TFLOPS (1/2) | Link | |
| RTX 4080 | Consumer/Gaming | 2022 | 9728 | 16GB | 717 GB/s | 48.7 TFLOPS | 761 GFLOPS (1/64) | Link | |
| RTX 4090 | Consumer/Gaming | 2022 | 16384 | 24GB | 1 TB/s | 82.6 TFLOPS | 1.3 TFLOPS (1/64) | Link | |
| RTX 3500 Ada | Workstation (Mobile) | 2023 | 5120 | 12GB | 432 GB/s | .084 GB/s | 23 TFLOPS | 360 GFLOPS (1/64) | Link |
| RTX 4000 Ada | Workstation | 2023 | 6144 | 20GB | 360 GB/s | .058 GB/s | 26.7 TFLOPS | 417 GFLOPS (1/64) | Link |
| RTX 6000 Ada | Workstation | 2023 | 18176 | 48GB | 960 GB/s | .053 GB/s | 91.1 TFLOPS | 1.4 TFLOPS (1/64) | Link |
| H100 (PCIe, SXM, NVL) | Datacenter | 2023 | 14592-16896 | 80GB | 2-3.9 TB/s | .137 GB/s | 51 TFLOPS | 26 TFLOPS (1/2) | Link, Link, Link |
| H200 | Datacenter | 2024 | 16896 | 141GB | 4.8 TB/s | 60-67 TFLOPS | 30-34 TFLOPS (1/2) | Link |
There are a couple interesting things to note here.
- All consumer and workstation GPUs have very poor FP64 performance compared to their FP32 performance. You have to step up to the more expensive datacenter GPUs to get extra FP64 (double-precision) performance. Our model relies on a lot of FP64 calculations currently, but we're exploring a refactor to use as much FP32 (single-precision) as possible to take advantage of cheaper hardware.
- Theoretical maximum compute is very difficult to achieve. Most of our problems wind up being bound by memory bandwidth.
- "Memory bandwidth" refers to the bandwidth from VRAM to the CUDA cores (not the PCIe transfer from CPU/RAM to GPU VRAM).
- Newer generations have less and less memory bandwidth per core - we have to work even harder to minimize data transfer to each core, while maximizing the amount of math we do.
- Within generations (comparing RTX 4000 to RTX 6000 Ada generation), GPUs seem to scale horizontally (more hardware at the same speed), which requires larger models to take advantage of.
- Performance can be really difficult to predict based on raw numbers. The Tesla GPU outperforms modern workstation cards by almost 2x for small systems, but falls back into line for the 637k cell model. There are so many architectural improvements from generation to generation that we haven't captured in this table - L1 cache sizes, register counts, cache latency, etc. The only way to know is to get access to hardware and test it.
- Cheaper consumer/gaming GPUs are surprisingly performant. If you're on a budget, they can still provide a lot of raw performance over a CPU solver.
- Older datacenter GPUs also work surprisingly well, and can be relatively inexpensive on the used market or cloud rental.
- RAS doesn't need much VRAM. We're going to be in the ~10 million cell range before that starts to become a concern with modern hardware. Paying for the extra VRAM in the higher end GPUs is superfluous at these model sizes.
Can I run this?
To run the GPU solver, you need to be running Windows 11, a compatible NVIDIA GPU, and recent drivers.
Checking your hardware
To check what GPU you may have installed in your system, launch Task Manager and select the 'Performance' tab from the left bar. Inside the main panel, scroll to the bottom to see if you have a GPU. You may have multiple, which should be labelled as "GPU 1", "GPU 2", etc. The most common reason to have multiple GPUs is if one of them is integrated into your CPU (typically Intel or AMD) and one of them is discrete (typically NVIDIA or AMD). In the image below, you can see I have an NVIDIA Quadro RTX 5000. To get more information on your card, you can check NVIDIAs website, e.g. here.
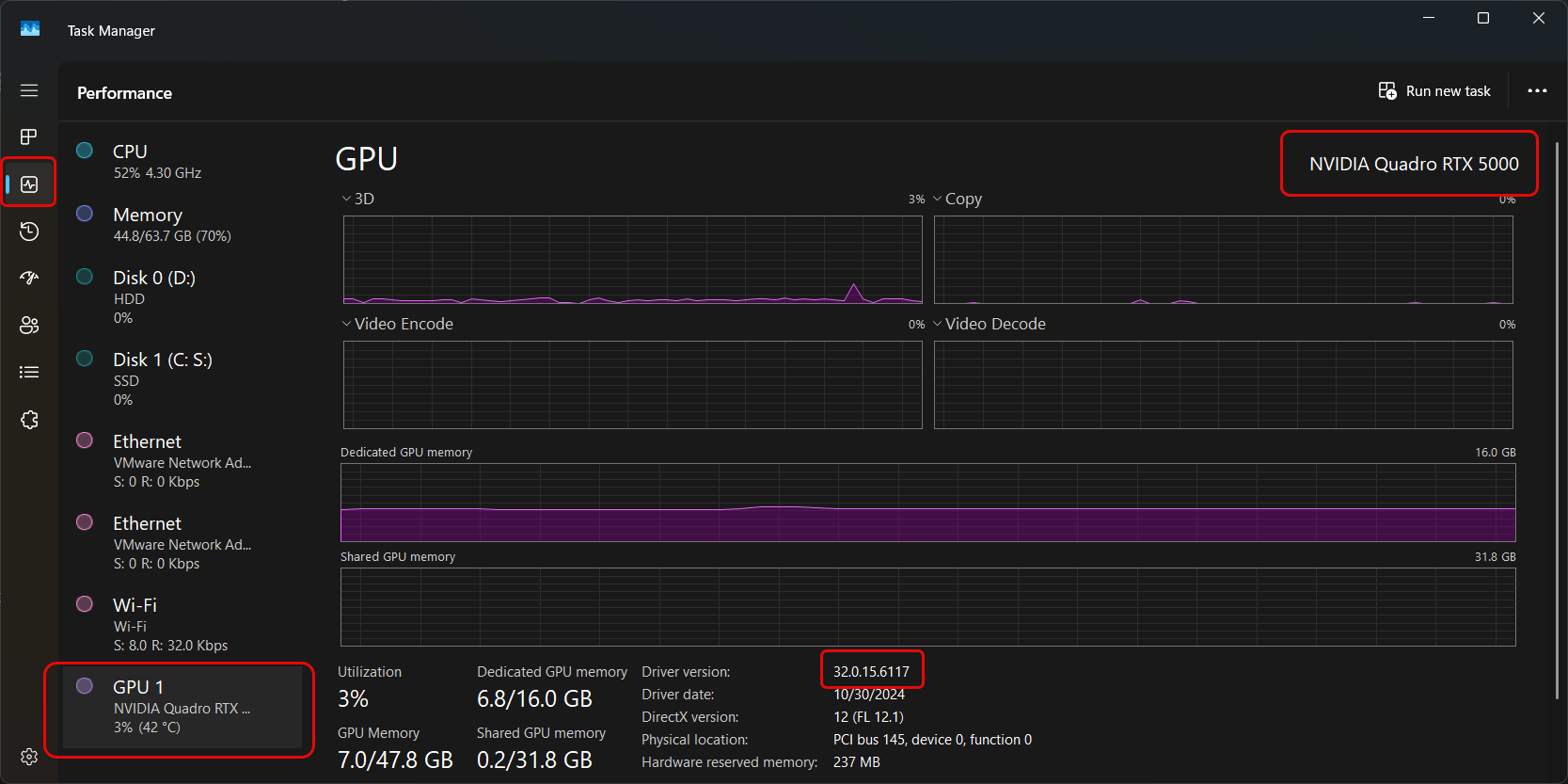
The other important piece of information to note is the Driver version - circled as 32.0.15.6117. We're interested in the last 5 digits, which corresponds to CUDA version 561.17, which is also accessible in the NVIDIA control panel.
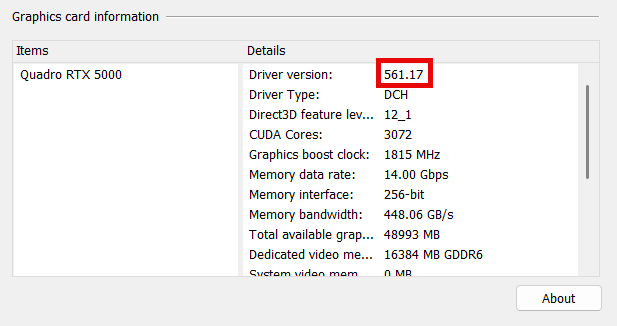
If you have an NVIDIA GPU and your CUDA driver version is >= 550.54, (our current minimum supported version) then you should be good to go! If your driver is out of date, you may need to contact your IT department or check Windows Update. If you're comfortable installing drivers manually, you can check for available drivers at NVIDIA's website.
What hardware should I buy?
The short answer is - we don't really know yet. We're still doing lots of experimenting internally. Typically engineering workstations would purchase cards like an RTX 4000 or RTX 6000 (previously the "Quadro" line of workstation graphics cards), but we're also experimenting with cheaper consumer graphics cards (designed for gaming) and seeing good results.
We recommend getting a graphics card with at least 12GB of VRAM (memory). We're still experimenting with larger models to learn how much memory RAS uses, but RAS isn't the only software utilizing your GPU. If you ever run afoul of VRAM limits, performance falls off a cliff. As a very coarse estimate, expect to use 1GB of VRAM for every 1 million cells in your system.
Our problem is very memory bandwidth bound, not compute bound. Unfortunately this means you have to step up to more expensive classes of cards to relieve some of this constraint.
The datacenter GPUs (represented by the Tesla V100, A100, and H100 in the compute benchmarks) improve performance dramatically over workstation cards, but that may change in the future. We're investigating how to move most of our solver to use FP32 calculations, which may change the relative performance characteristics of those GPUs. While the solver is rapidly iterating and evolving, we don't (yet) recommend going out and buying the expensive datacenter GPUs. If you have them laying around however, they may dramatically improve runtimes.
Be cautious about confusing model numbers. The Quadro RTX 6000 is older than the RTX A6000, which is older than the RTX 6000 Ada.