Download PDF
Download page Mixed Populations Workshop.
Mixed Populations Workshop

Software
The following software was used to create this example:
HEC-SSP v2.3-beta 5: https://www.hec.usace.army.mil/software/hec-ssp/download.aspx
CRAN R version 4.2.2 or newer
RStudio version 2023.03.0+386 or newer
Introduction
In fitting an analytical probability distribution to a sample of flood events, we make the assumption that the flood events are independent and identically distributed (IID). At many locations in the United States, floods are produced by multiple mechanisms. A flood series comprised of floods caused by different physical processes is called a mixed population. We are violating the "identically distributed" assumption at sites where floods are caused by multiple mechanisms. The "identification and treatment of mixed distributions" was listed in the Future Studies section of the latest two versions of Federal flood frequency guidelines, Bulletin 17B (1982) and Bulletin 17C (2019).
The method used in this tutorial to identify flood causal mechanism is one possible way to separate flood events in a mixed flood series. This tutorial is not Federal guidance.
Site Information: Merced River
The Merced River originates in the Sierra Nevada and flows through Yosemite National Park, before joining the San Joaquin River in the Central Valley of California. This tutorial will investigate floods at USGS 11266500 Merced River at Pohono Bridge near Yosemite, CA. The gage has a drainage area of 321 square miles. Annual peak flows at the gage are available starting in WY1918 and continuous mean daily streamflow data is available starting in WY1917.

This workshop has four tasks and will use HEC-SSP and R to compute the results.
- Examine flood event data in HEC-SSP
- Compute flood event contributions from rain and snowmelt
- Investigate the sensitivity of flood type classification to thresholds
- Fit analytical probability distributions to flood type subsets
Task 1: Examine Flood Event Data in HEC-SSP
- Open HEC-SSP v2.3 beta.5.
- Create a new study by selecting File | New Study... (or use the keyboard shortcut Ctrl+N).
- Enter "MercedRiver" as the Study Name. Leave the Unit System set to English and the Coordinate System set to Geographic.
- Save the file in an appropriate directory and click the OK button.
- Open the Data Import Wizard by selecting Data | New | Using Import Wizard... or by right-clicking on the Data folder and selecting New | Using Import Wizard....
- Leave the default selections on the Create New Data Set screen of the data importer. Click the Next> button.
- Select the radio button next to USGS Website and click the Next> button.
- Leave the default selections for the Data Type and Retrieve Data for sections (Annual Peak Data and Flow, respectively).
- In the Station ID's section, select Get USGS Station ID's by State. Click the Get ID's for State button and select California.
- Click the OK button to close the dialog box. Click the Next> button.
- In the Basin Name (A Part) column, enter *pohono*.

The asterisk (*) can be used as a wildcard to search for all strings that contain what has been typed.
- Check the box next to USGS 11266500 Merced River at Pohono Bridge, CA.
- Click the Next> button.
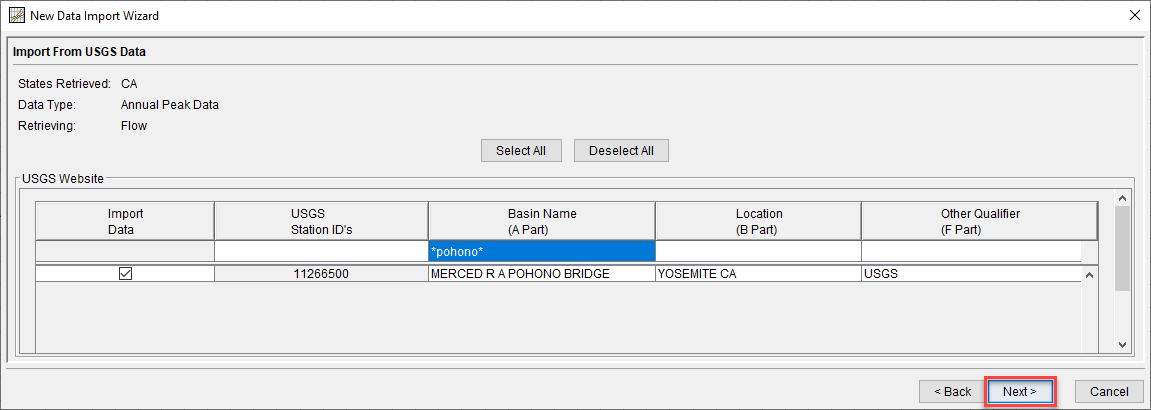
- Click Import.
- When the import is complete, open the data importer again.
- Leave the default selections on the Create New Data Set screen of the data importer. Click the Next> button.
- Select the radio button next to USGS Website and click the Next> button.
- Change the Data Type to Daily. Under Daily Options, check the box next to Retrieve Period of Record and select UTC as the time zone.
- Select California in the Station ID's section.
- Search for the gage and check the box next to USGS 11266500 Merced River at Pohono Bridge, CA.
- Click Next> and Import.
- You should have two datasets in the Data folder.

- Right click on the Annual Peak dataset and select Year-Over-Year Plot.

- Leave the Year Specification as Water Year (starts Oct 1). Click Plot.
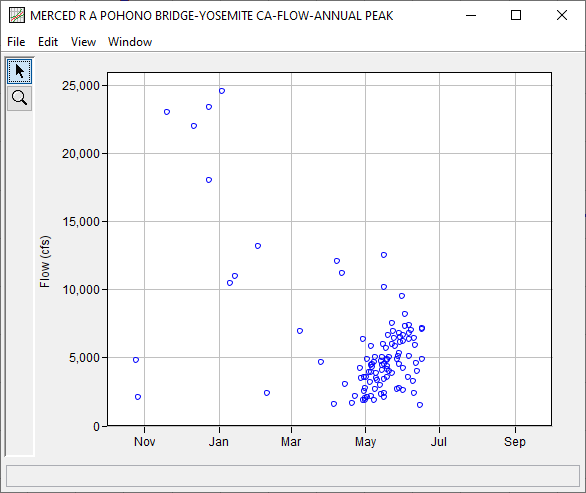
QUESTION 1. What do you notice about the seasonality/timing of annual peak flows?
The timing of annual peak flows exhibits strong seasonality. Most annual peak flows occur in the spring (April - June) and coincide with spring snowmelt. However, the springtime annual peak floods tend to have smaller magnitudes than events that occur in the fall and winter months. The fall and winter flood events at this site are up to 10x larger than springtime floods.
- Create a new Bulletin 17 analysis by right-clicking on the Bulletin 17 folder and selecting New....
- Enter "MercedRiver_B17C" as the Name.
- Select the Annual Peak dataset from the Flow Data Set drop-down menu.
- Leave the default selections on all tabs. Click Compute.
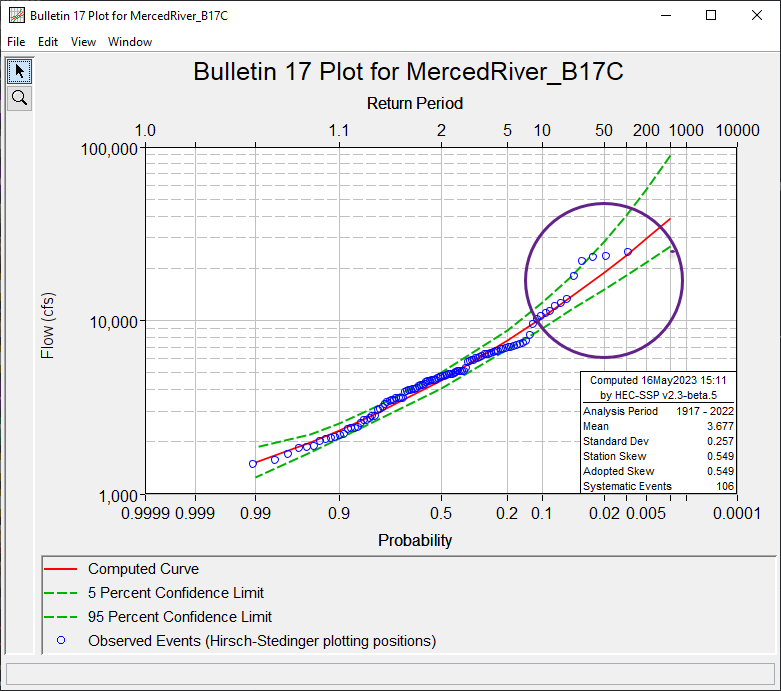
Click Plot Curve.
QUESTION 2. What do you notice about the fit of the LP3 curve?The plotting positions have a pronounced S-shape which is indicative of multiple flood causal mechanisms. The fit of the LP3 distribution to the data isn't great at the upper end of the curve.
- Next, extract a Partial Duration Series (PDS) from the mean daily streamflow data. Right-click on the daily streamflow dataset and select Filter Data...

- Select the Peaks tab.
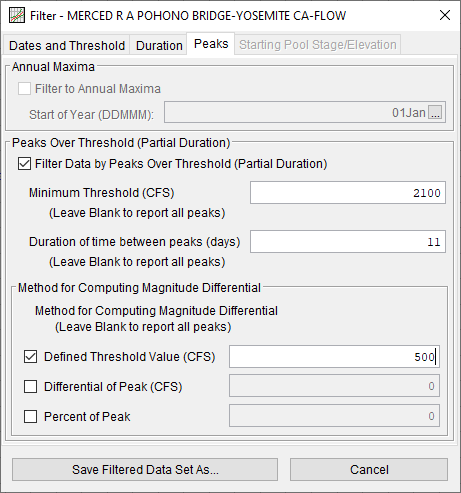
- In the Peaks Over Threshold (Partial Duration) section, check the box next to Filter Data by Peaks Over Threshold (Partial Duration).
- The flood separation and threshold values were determined using the procedures described in Flood Separation and Threshold Choice Workshop. Diagnostic plots (the threshold-event trade-off plot, the Pareto shape parameter plot, and the mean excess plot) were used to determine an appropriate flow threshold. A time-based separation with recession was used. A minimum separation of 11 days (computed using the \lceil 5+\ln(DA) \rceil rule) and recession threshold of 500 cfs were used.

Where does 5 + ln(DA) come from?
The \lceil 5+\ln(DA) \rceil computation is included in Appendix 14 of Bulletin 17 (1976) and Bulletin 17B (1982) to ensure independence between events.
- Enter the following:
- Minimum Threshold (CFS): 2100
- Duration of time between peaks (days): 11
- In the Method for Computing Magnitude Differential section, check the box next to Defined Threshold Value (CFS). Enter a value of 500.
- Click Save Filtered Data Set As....
- Name the new dataset as in the image below.
- Click the OK button.
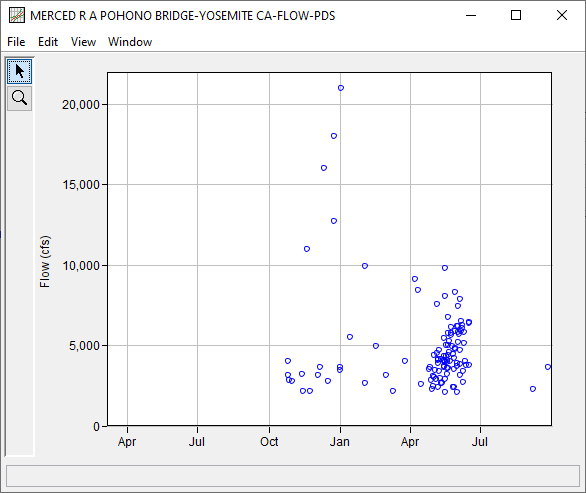
- Right click on the newly created PDS dataset and select Year-Over-Year Plot.
QUESTION 3. What do you notice about the seasonality/timing of PDS flood events?
The timing and seasonality of the PDS flood events is the same as that of the annual peak flows (see ANSWER 1).
Task 2: Compute PDS Flood Event Contributions from Rain and Snow
- Download the MixedPopulationsWorkshop.R script and the
pds_events.Rdatafile to the same folder on your computer. - In RStudio, set the working directory to the file directory containing these files.
- Open the
MixedPopulationsWorkshop.Rscript in RStudio. - Run lines 1-54. This will load libraries, load mean daily streamflow data for WY1982-2021 using the
dataRetrievallibrary, extract the annual maximum daily flow, load the previously developed partial duration series data frame, and plot the mean daily flow (PDS as blue diamonds and AMS as magenta circles). Note that the AMS and PDS were developed from the mean daily flow time series.
QUESTION 4. How many events are in the AMS and PDS? Are there differences between the PDS and AMS?The AMS is comprised of 41 events since we are working with 41 years of streamflow record. The PDS is comprised of 44 events.
Most of the events in the AMS were also selected in the PDS. However, the PDS includes multiple events per year in WY 1982, 1983, 1997, and 2017 and does not include smaller annual peak flows in WY 1988, 2014, 2015, and 2021.

Steps 2-5 were performed for you. In Task 3, you will classify the partial duration series events during the period WY 1982-2021 by flood causal mechanism. The time period WY 1982-2021 corresponds to the availability of spatially distributed snow-related data from the University of Arizona dataset. - Define an antecedent period to compute relevant meteorologic indices for flood type attribution. In this tutorial, an antecedent period of \lceil 5+\ln(DA) \rceil where DA is in square miles, was used.
- Compute basin-average cumulative precipitation during the event antecedent period using the Livneh et al. (2013) precipitation dataset for WY1982-2011 events.
- Compute basin-average cumulative precipitation during the event antecedent period using the National Weather Service Analysis of Record for Calibration (AORC) dataset for WY2011-2021 events.
- Compute basin-average maximum decrease in snow water equivalent (SWE) during the event antecedent period using the University of Arizona (UA) dataset.
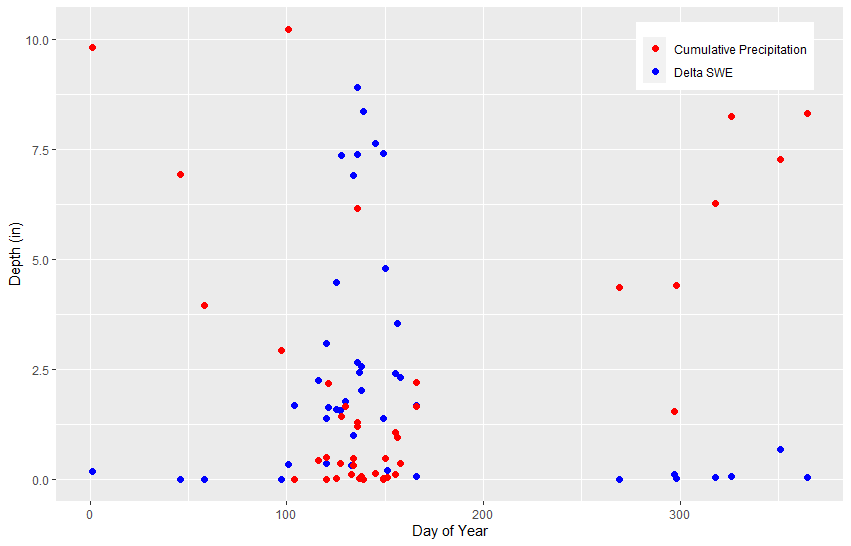
Run lines 57-65 to plot the depths of precipitation and snowmelt contributing to each PDS event against day of year.
QUESTION 5. What do you notice about the relative contribution from precipitation vs. snowmelt before flood events in the PDS?
The contribution from snowmelt is highest during the springtime events. The contribution from precipitation during this time period varies. Flood events during the fall and winter months appear to be driven by rainfall, with little to no contribution from snowmelt.
Task 3: Investigate Sensitivity of Flood Type Classification to Thresholds
Step 1: Use Absolute Thresholds to Separate Rain and Snowmelt Events
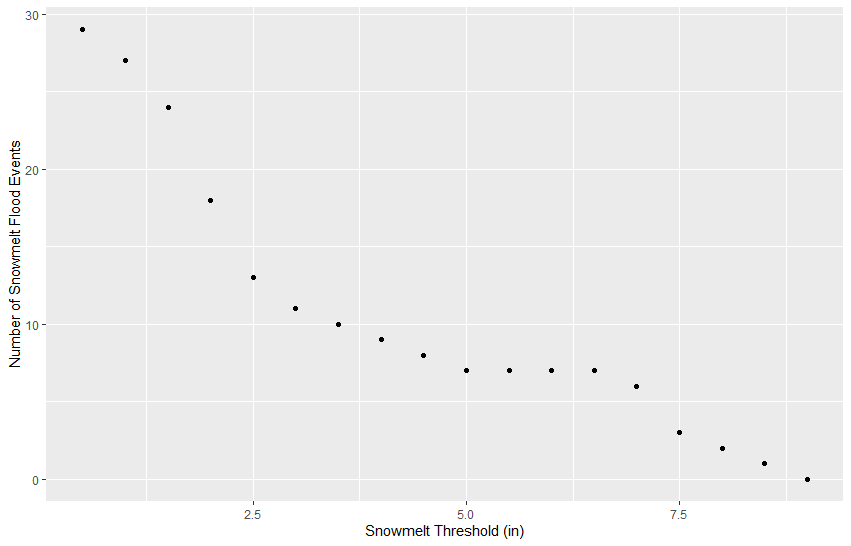
Run lines 70-82 to plot the number of floods classified as snowmelt events against the snowmelt threshold in inches.
QUESTION 6. How many events were classified as snowmelt- and rain-driven using various snowmelt contribution (in) thresholds?
Snowmelt contribution thresholds varying from 0.5 to 9 inches (in 0.5 inch increments) were investigated. The figure below shows the number of flood events classified as snowmelt-driven based on the selected snowmelt threshold.
Step 2: Use Relative Thresholds to Separate Rain and Snowmelt Events
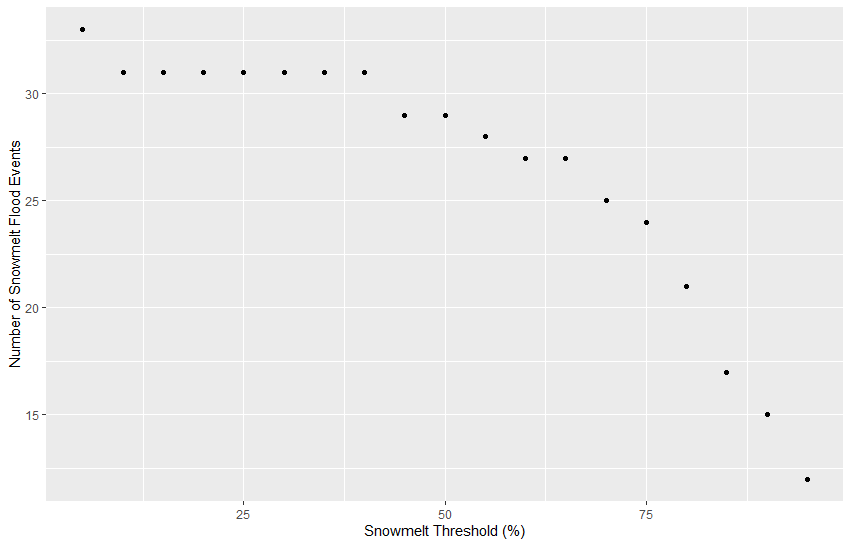
Run lines 85-97 to plot the number of floods classified as snowmelt events against the snowmelt threshold in %.
QUESTION 7. How many events were classified as snowmelt- and rain-driven using various snowmelt contribution (%) thresholds?
Snowmelt contribution thresholds varying from 5% to 95% (in 5% increments) were investigated. The figure below shows the number of flood events classified as snowmelt-driven based on the selected snowmelt threshold.
Task 4: Fit Analytical Probability Distributions to Flood Type Subsets
In this task, you will compute mixed (i.e. no separation) and combined frequency curves. The combined frequency curve will be developed using the probability of union. The combined exceedance probability is computed as:
P_c = 1 - \prod_{i=1}^{n} (1 - P_i) which simplifies to P_c = 1 - (1 - P_r_a_i_n)(1 - P_s_n_o_w) = P_r_a_i_n + P_s_n_o_w - P_r_a_i_n * P_s_n_o_w for two populations.
The combined non-exceedance probability is computed as:
F(x) = 1 - P_c = F_r_a_i_n(x)*F_s_n_o_w(x)
Step 1: Use a 75% Snowmelt Contribution Threshold
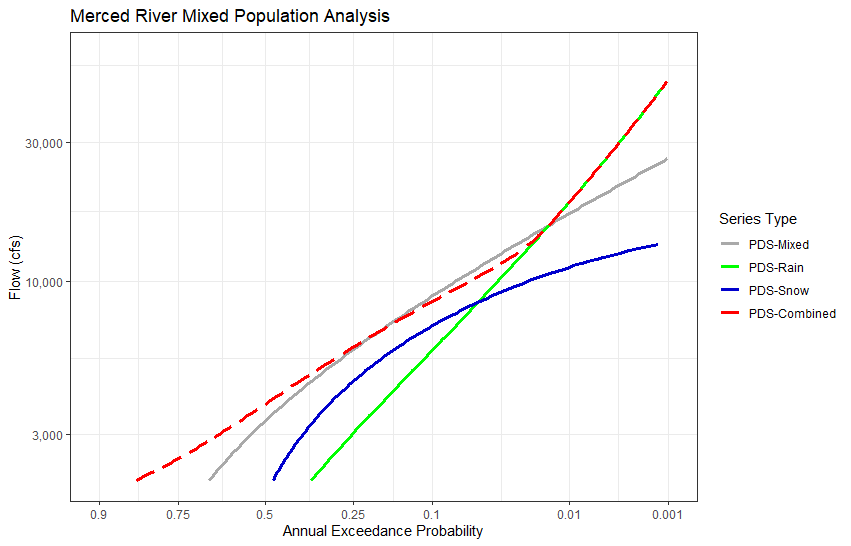
Run lines 101-155. This will (1) divide the PDS into rain and snowmelt events using a 75% snowmelt contribution threshold, (2) fit the generalized Pareto distribution to the mixed (i.e. no separation), rain, and snowmelt floods using L-moments, (3) generate flows ranging from the threshold value to 60,000 cfs, (4) compute the annual non-exceedance probability for each of the generated flows using the Langbein adjustment, (5) compute the combined frequency curve using probability of union, (6) plot the frequency curves, and (7) compute the 1% and 0.1% annual exceedance probability (AEP) quantiles from the mixed and combined curves.
Note that probabilities computed from the functions lmomco::cdfgpa and lmomco::fpds2f are non-exceedance probabilities. The frequency curve x-axis labels were replaced with AEP as is common in hydrology.
QUESTION 8. What is the generalized Pareto distribution shape parameter for the mixed (i.e. no separation) flood series? View the gp_mixed variable in the Environment tab.
The mixed PDS flood sample is described by a generalized Pareto distribution shape parameter of -0.072 (fit using L-moments).
QUESTION 9. Using a 75% snowmelt contribution threshold, how many PDS flood events were classified as snowmelt- and rain-driven? What is the generalized Pareto shape parameter for each flood subset? What is the difference in the 1% and 0.1% AEP quantiles between the mixed and combined curves (view the qua_combined, qua_mixed, and qua_diff variables in the Environment tab)?
- Number of rain events: 20
- Number of snowmelt events: 24
- GPA distribution shape parameter (rain): -0.344
- GPA distribution shape parameter (snow): 0.265
- 1% AEP quantiles
- Combined: 19,745 cfs
- Mixed: 17,055 cfs
- Difference: 2,690 cfs
- 0.1% AEP quantiles
- Combined: 48,707 cfs
- Mixed: 26,469 cfs
- Difference: 22,239 cfs

Step 2: Use a 1.25 in Snowmelt Contribution Threshold
Run lines 158-206. This will perform the same computations described in Step 1 but the PDS will be divided into rain and snowmelt events using a 1.25 inch snowmelt contribution threshold.
QUESTION 10. Using a 1.25 in snowmelt contribution threshold, how many PDS flood events were classified as snowmelt- and rainfall-driven? What is the generalized Pareto shape parameter for each flood subset? What is the difference in the 0.1% AEP flow quantile between the mixed and combined curves (view the qua_combined, qua_mixed, and qua_diff variables in the Environment tab)?
- Number of rain events: 18
- Number of snowmelt events: 26
- GPA distribution shape parameter (rain): -0.382
- GPA distribution shape parameter (snow): 0.219
- 1% AEP quantiles
- Combined: 18,589 cfs
- Mixed: 17,055 cfs (same as in Step 1)
- Difference: 1,535 cfs
- 0.1% AEP quantiles
- Combined: 48,993 cfs
- Mixed: 26,469 cfs (same as in Step 1)
- Difference: 22,524 cfs
QUESTION 11. Comment on the differences between the parameters obtained using a 75% and 1.25 in snowmelt contribution threshold. Also, comment on the differences in the generalized Pareto distribution parameters between the mixed, rain, and snow populations.
The GPA distribution parameters for the two methods of flood typing are similar. In both cases, the scale parameter is higher for the snow floods than for the rain floods, indicating that the magnitude of snow floods has a wider spread than rain floods. The snow floods are described by a positive shape parameter, implying that the distribution has an upper-bound (EV Type II/Fréchet distribution). The upper bound was computed on line 114. The rain floods are described by a negative shape parameter, implying that the distribution has a lower-bound (EV Type III/Weibull distribution).
The GPA shape parameter for the mixed flood series is slightly negative (-0.072). The shape parameters for the rain (-0.344/-0.382) and snow floods (0.265/0.219) are substantially different than the mixed shape parameter.
QUESTION 12. Do you think that 2 populations (rain and snowmelt floods) are sufficient to describe floods at this site? If not, why?
More isn't always better. However, many of the largest floods at the site have been described as "rain-on-snow" events with some contribution from precipitation falling as rain and melting the snowpack: https://www.nps.gov/yose/learn/management/1997-flood-recovery.htm. You could define a third flood subset for rain-on-snow events. However, we only evaluated 40 years of record and 44 flood events so adding a 3rd flood type would reduce the sample sizes in each flood type and make it difficult to fit reasonable analytical probability distributions.